
[EMNLP2025] "LightRAG: Simple and Fast Retrieval-Augmented Generation"
Copy the command below to clone the repository to your machine.


![]()


|
|
Fix, Recursive, Vector, and Paragraph.
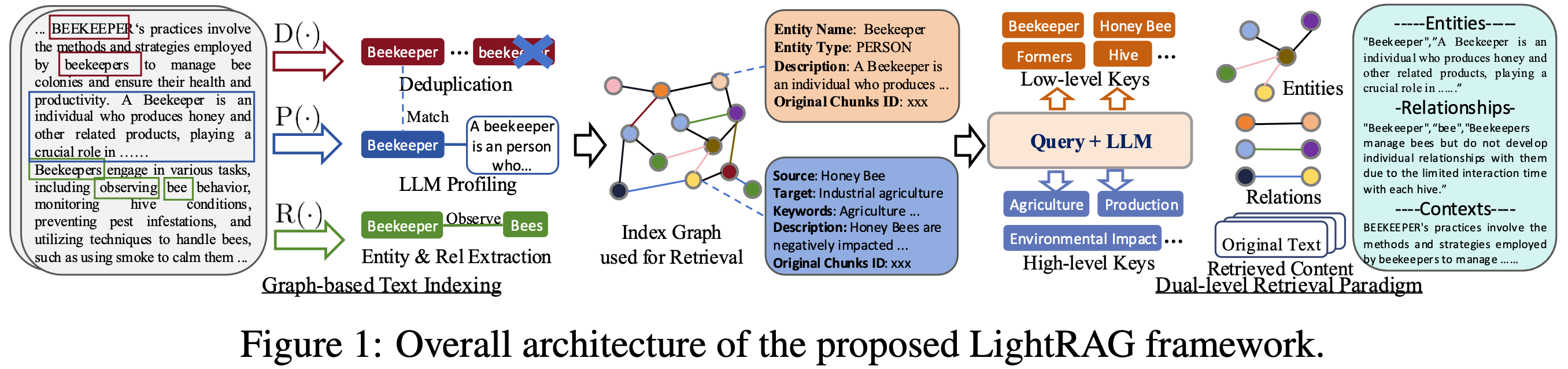
Figure 1: LightRAG Indexing Flowchart - Img Caption : Source
Figure 2: LightRAG Retrieval and Querying Flowchart - Img Caption : Source
💡 Using uv for Package Management: This project uses uv for fast and reliable Python package management. Install uv first: curl -LsSf https://astral.sh/uv/install.sh | sh (Unix/macOS) or powershell -c "irm https://astral.sh/uv/install.ps1 | iex" (Windows)
Note: You can also use pip if you prefer, but uv is recommended for better performance and more reliable dependency management.
📦 Offline Deployment: For offline or air-gapped environments, see the Offline Deployment Guide for instructions on pre-installing all dependencies and cache files.
### Install LightRAG Server as tool using uv (recommended)
uv tool install "lightrag-hku[api]"
### Or using pip
# python -m venv .venv
# source .venv/bin/activate # Windows: .venv\Scripts\activate
# pip install "lightrag-hku[api]"
### Build front-end artifacts
cd lightrag_webui
bun install --frozen-lockfile
bun run build
cd ..
# Setup env file
# Obtain the env.example file by downloading it from the GitHub repository root
# or by copying it from a local source checkout.
cp env.example .env # Update the .env with your LLM and embedding configurations
# Launch the server. It binds to all interfaces (0.0.0.0) by default.
# SECURITY: before exposing it on a network, configure authentication in .env
# (LIGHTRAG_API_KEY, or AUTH_ACCOUNTS together with TOKEN_SECRET), or bind to
# 127.0.0.1 for local-only access; without auth every endpoint is public.
# Note: the Ollama-compatible /api/* routes stay open by default for client
# compatibility; set WHITELIST_PATHS=/health to require auth on them too.
lightrag-server
git clone https://github.com/HKUDS/LightRAG.git
cd LightRAG
# Bootstrap the development environment (recommended)
make dev
source .venv/bin/activate # Activate the virtual environment (Linux/macOS)
# Or on Windows: .venv\Scripts\activate
# make dev installs the test toolchain plus the full offline stack
# (API, storage backends, and provider integrations), then builds the frontend.
# Run make env-base or copy env.example to .env before starting the server.
# Equivalent manual steps with uv
# Note: uv sync automatically creates a virtual environment in .venv/
uv sync --extra test --extra offline
source .venv/bin/activate # Activate the virtual environment (Linux/macOS)
# Or on Windows: .venv\Scripts\activate
### Or using pip with virtual environment
# python -m venv .venv
# source .venv/bin/activate # Windows: .venv\Scripts\activate
# pip install -e ".[test,offline]"
# Build front-end artifacts
cd lightrag_webui
bun install --frozen-lockfile
bun run build
cd ..
# setup env file
make env-base # Or: cp env.example .env and update it manually
# Launch API-WebUI server
lightrag-server
git clone https://github.com/HKUDS/LightRAG.git
cd LightRAG
cp env.example .env # Update the .env with your LLM and embedding configurations
# modify LLM and Embedding settings in .env
docker compose up
Historical versions of LightRAG docker images can be found here: LightRAG Docker Images
Official GHCR images published by GitHub Actions are signed with Sigstore Cosign using GitHub OIDC. See docs/DockerDeployment.md for verification commands.
On Apple Silicon (macOS 26) without Docker Desktop, you can run the same Postgres/Neo4j/Milvus storage stack on Apple's native
containerruntime — see docs/AppleContainerSetup.md.
Instead of editing env.example by hand, use the interactive setup wizard to generate a configured .env and, when needed, docker-compose.final.yml:
make env-base # Required first step: LLM, embedding, reranker
make env-storage # Optional: storage backends and database services
make env-server # Optional: server port, auth, and SSL
make env-base-rewrite # Optional: force-regenerate wizard-managed compose services
make env-storage-rewrite # Optional: force-regenerate wizard-managed compose services
make env-security-check # Optional: audit the current .env for security risks
For full description of every target see docs/InteractiveSetup.md.
The native docx parser's opt-in smart_heading engine parameter uses spaCy for sentence/NER heuristics. The spaCy runtime is already included in the api extra — only the two pinned language models (zh_core_web_sm / en_core_web_sm 3.8.0, GitHub release wheels not published on PyPI) need one extra step:
lightrag-download-cache --spacy --spacy-install
Enable smart_heading per file/rule (e.g. LIGHTRAG_PARSER=docx:native(smart_heading=true)), or globally in .env:
# .docx files routed to the native engine get smart_heading by default;
# opt a file back out with an explicit native(smart_heading=false) rule/hint.
DOCX_SMART_HEADING=true
When the global switch is on (or a LIGHTRAG_PARSER rule carries native(smart_heading=true)), the server verifies the models at startup and fails fast with install guidance if they are missing. Deployments that never enable smart_heading need no models. The main Docker image ships the models pre-installed (the lite image does not); for air-gapped hosts see the Offline Deployment Guide.
LightRAG is a lightweight knowledge-graph RAG framework and an efficient alternative to Microsoft GraphRAG. It adopts a dual-layer architecture to manage both knowledge graphs (KGs) and vector embeddings, effectively bridging the gap between traditional vector-based RAG and graph-based RAG approaches. Designed for high scalability, LightRAG addresses key challenges in large-scale graph indexing and retrieval, including heavy computational overhead, slow response times, and the high cost of incremental updates. While supporting large datasets, LightRAG can still deliver exceptionally high RAG quality, even when paired with a 30B open-source large language model (LLM).
Starting from version v1.5, LightRAG has officially introduced analysis and retrieval capabilities for multimodal documents:
The LightRAG server offers not only a web-based UI for exploring LightRAG functionalities but also a comprehensive REST API. For more information about the LightRAG server, please refer to LightRAG Server.
LightRAG requires LLM/VLMs of four different roles during its workflow. You should configure models with different capabilities and speeds for different roles to strike a balance between performance and processing speed. LightRAG has higher capability requirements for Large Language Models (LLMs) than traditional RAG because it requires LLMs to perform complex entity-relation extraction tasks from documents. During the query phase, the LLM needs to process a large volume of retrieved information, including entities, relationships, and text chunks. This requires the model to have the capability of generating high-quality responses in long, noisy contexts.
Recommended models by role:
EXTRACT): Entity-relation extraction runs on every text chunk, so a fast, cost-effective mainstream model is enough — a non-thinking model (reasoning/thinking mode disabled) is strongly recommended to avoid slow, expensive extraction. Good hosted options include GPT-5.6-luna, Claude Haiku, or Gemini-mini internationally, and DeepSeek-V4-lite or Kimi in China. For local deployment, Qwen3-30B-A3B-Instruct is a reasonable minimum.QUERY): This model writes the final answer from long, noisy retrieved context, so it should be stronger than the extraction model in order to maximize answer quality. Choose a higher-tier model from the same families; a thinking-capable model is fine here.KEYWORD): A lightweight, latency-sensitive step that must use a non-thinking model to keep query latency low; a fast model comparable to the extraction one is sufficient.VLM): Any mainstream multimodal model with image-input support works. For local deployment, consider Qwen3.6-35B-A3B.Within your acceptable latency and cost budget, prefer the highest-scoring model available (based on public benchmarks/leaderboards). For detailed model configurations, please refer to RoleSpecificLLMConfiguration.md
LightRAG supports five query modes:
The default query mode for LightRAG is mix. Using mix mode generally yields the most ideal query results. The mix mode takes slightly longer than naive, while other query modes are roughly comparable in latency.
When choosing an Embedding model, pay attention to its multilingual support capabilities. Since LightRAG's retrieval quality has limited dependency on the Embedding model, it is recommended to choose low-dimensional and fast models. Any mainstream, up-to-date embedding model works well; for local deployment, BAAI/bge-m3 is a solid choice. We highly recommend deploying the Embedding model locally to achieve the best performance.
Important Note: The Embedding model must be determined before document indexing, and the same model must be used in the query phase. Once selected, embedding models generally cannot be changed. If changed, you will need to re-embed all text chunks, entities, and relationships. LightRAG does not currently provide a re-embedding tool. Some storage backends (e.g., PostgreSQL) require the vector dimension to be defined when creating tables for the first time, so changing the Embedding model requires deleting vector-related tables so LightRAG can recreate them.
Enabling the Rerank option during the query phase can significantly improve query quality. However, enabling Rerank typically introduces a 1–2 second delay. To minimize latency, it is highly recommended to deploy the Rerank model locally. Any mainstream, up-to-date reranker works; for local deployment, BAAI/bge-reranker-v2-m3 is recommended. For configuration details, please refer to the .env.example file. Unlike Embedding models, the Rerank model can be changed at any time during the query phase.
The default pipeline configuration in LightRAG does not allow the system to perform at its best. The quality of document parsing greatly impacts document indexing and querying. Therefore, we recommend configuring the pipeline to enable the MinerU parsing engine and activating the pipeline's image analysis features. Suggested configuration:
LIGHTRAG_PARSER=*:native-iteP,*:mineru-iteP,*:legacy-R
VLM_PROCESS_ENABLE=true
VLM_LLM_MODEL=<your_vlm_model_name>
Since the cloud-based MinerU service has limitations on usage, file size, and page count, it is recommended to use a locally deployed MinerU. For details on configuring the file processing pipeline, please refer to FileProcessingPipeline.md
For large-scale document processing, you need to improve concurrency. Key environment variables related to concurrent file processing include:
MAX_PARALLEL_INSERT should ideally be set to about 1/3 of MAX_ASYNC_LLM.# Sample Configuration
MAX_ASYNC_LLM=8
MAX_PARALLEL_INSERT=3
EMBEDDING_FUNC_MAX_ASYNC=16
EMBEDDING_BATCH_NUM=32
LightRAG requires four types of backend storage:
By default, LightRAG's storage backends are file-persisted, in-memory databases. These default storages are intended only for development and debugging, and are not suitable for production. In a production environment, if you prefer a single backend to handle all four storage types, you can choose PostgreSQL, MongoDB, or OpenSearch. Alternatively, you can select specialized databases for vector or graph storage, such as using Milvus or Qdrant for vector storage, and Neo4j or Memgraph for graph storage.
During the document insertion stage, you may also want to adjust the following environment variables based on your needs:
Chinese, English.entity/relation can be associated with.entity/relation exceeds its associated text chunk limit (by default it stops updating, because at that point the entity-relation description is already rich enough and further updates add little value; skipping updates can greatly speed up knowledge base construction).entity/relation can be associated with; once this limit is exceeded, new file names are no longer written to the vector storage.LLM timeouts during entity-relation extraction usually trace back to one of three causes. Identify the cause, then apply the matching remedy (the parameters can be combined):
*_LLM_TIMEOUT — either the global LLM_TIMEOUT or the role-specific EXTRACT_LLM_TIMEOUT for the extraction phase. Note that the effective execution timeout is twice the configured value, so EXTRACT_LLM_TIMEOUT=300 allows up to 600 seconds.OPENAI_LLM_MAX_TOKENS or OPENAI_LLM_MAX_COMPLETION_TOKENS (the correct parameter name depends on the LLM provider — see env.example). A useful sizing rule is max_output_tokens < LLM_TIMEOUT × tokens_per_second (e.g., 9000 < 240s × 50 tps).P) chunking strategy (e.g., LIGHTRAG_PARSER=...-iteP), set CHUNK_P_DROP_REFERENCES=true to automatically drop the trailing reference section before chunking. This prevents references from generating a flood of low-value entities and relations, a common source of timeouts. It can also be enabled per file via the filename hint paper.[-P(drop_rf=true)].pdf; related detection knobs (CHUNK_P_REFERENCES_TAIL_N, CHUNK_P_REFERENCES_HEADINGS) are documented in env.example.During the document query stage, you may also want to adjust the following environment variables based on your needs:
entities, relations, and text chunks. The lengths of entities and relations can be controlled independently, while the text chunk length is determined by subtracting the entity and relation lengths from the total length.⚠️ For integration into your project, we strongly recommend using the REST API provided by the LightRAG Server. The LightRAG SDK is primarily intended for embedded applications or academic research and evaluation purposes.
cd LightRAG
# 注意: uv sync 会自动在 .venv/ 目录创建虚拟环境
uv sync
source .venv/bin/activate # 激活虚拟环境 (Linux/macOS)
# Windows 系统: .venv\Scripts\activate
# 或: pip install -e .
uv pip install lightrag-hku
# 或: pip install lightrag-hku
To get started with LightRAG core, refer to the sample codes available in the examples folder. Additionally, a video demo demonstration is provided to guide you through the local setup process. If you already possess an OpenAI API key, you can run the demo right away:
### you should run the demo code with project folder
cd LightRAG
### provide your API-KEY for OpenAI
export OPENAI_API_KEY="sk-...your_opeai_key..."
### download the demo document of "A Christmas Carol" by Charles Dickens
curl https://raw.githubusercontent.com/gusye1234/nano-graphrag/main/tests/mock_data.txt > ./book.txt
### run the demo code
python examples/lightrag_openai_demo.py
For a streaming response implementation example, please see examples/lightrag_openai_compatible_demo.py. Prior to execution, ensure you modify the sample code's LLM and embedding configurations accordingly.
Note 1: When running the demo program, please be aware that different test scripts may use different embedding models. If you switch to a different embedding model, you must clear the data directory (./dickens); otherwise, the program may encounter errors. If you wish to retain the LLM cache, you can preserve the kv_store_llm_response_cache.json file while clearing the data directory.
Note 2: Only lightrag_openai_demo.py and lightrag_openai_compatible_demo.py are officially supported sample codes. Other sample files are community contributions that haven't undergone full testing and optimization.
For detailed instructions on using the SDK, please refer to docs/ProgramingWithCore.md. Some LightRAG features are not exposed via the REST API and are accessible only through the SDK. These features are typically experimental and may not be compatible with future versions.
LightRAG consistently outperforms NaiveRAG, RQ-RAG, HyDE, and GraphRAG across agriculture, computer science, legal, and mixed domains. For the full evaluation methodology, prompts, and reproduce steps, see docs/Reproduce.md.
Overall Performance Table
| Agriculture | CS | Legal | Mix | |||||
|---|---|---|---|---|---|---|---|---|
| NaiveRAG | LightRAG | NaiveRAG | LightRAG | NaiveRAG | LightRAG | NaiveRAG | LightRAG | |
| Comprehensiveness | 32.4% | 67.6% | 38.4% | 61.6% | 16.4% | 83.6% | 38.8% | 61.2% |
| Diversity | 23.6% | 76.4% | 38.0% | 62.0% | 13.6% | 86.4% | 32.4% | 67.6% |
| Empowerment | 32.4% | 67.6% | 38.8% | 61.2% | 16.4% | 83.6% | 42.8% | 57.2% |
| Overall | 32.4% | 67.6% | 38.8% | 61.2% | 15.2% | 84.8% | 40.0% | 60.0% |
| RQ-RAG | LightRAG | RQ-RAG | LightRAG | RQ-RAG | LightRAG | RQ-RAG | LightRAG | |
| Comprehensiveness | 31.6% | 68.4% | 38.8% | 61.2% | 15.2% | 84.8% | 39.2% | 60.8% |
| Diversity | 29.2% | 70.8% | 39.2% | 60.8% | 11.6% | 88.4% | 30.8% | 69.2% |
| Empowerment | 31.6% | 68.4% | 36.4% | 63.6% | 15.2% | 84.8% | 42.4% | 57.6% |
| Overall | 32.4% | 67.6% | 38.0% | 62.0% | 14.4% | 85.6% | 40.0% | 60.0% |
| HyDE | LightRAG | HyDE | LightRAG | HyDE | LightRAG | HyDE | LightRAG | |
| Comprehensiveness | 26.0% | 74.0% | 41.6% | 58.4% | 26.8% | 73.2% | 40.4% | 59.6% |
| Diversity | 24.0% | 76.0% | 38.8% | 61.2% | 20.0% | 80.0% | 32.4% | 67.6% |
| Empowerment | 25.2% | 74.8% | 40.8% | 59.2% | 26.0% | 74.0% | 46.0% | 54.0% |
| Overall | 24.8% | 75.2% | 41.6% | 58.4% | 26.4% | 73.6% | 42.4% | 57.6% |
| GraphRAG | LightRAG | GraphRAG | LightRAG | GraphRAG | LightRAG | GraphRAG | LightRAG | |
| Comprehensiveness | 45.6% | 54.4% | 48.4% | 51.6% | 48.4% | 51.6% | 50.4% | 49.6% |
| Diversity | 22.8% | 77.2% | 40.8% | 59.2% | 26.4% | 73.6% | 36.0% | 64.0% |
| Empowerment | 41.2% | 58.8% | 45.2% | 54.8% | 43.6% | 56.4% | 50.8% | 49.2% |
| Overall | 45.2% | 54.8% | 48.0% | 52.0% | 47.2% | 52.8% | 50.4% | 49.6% |
Ecosystem & Extensions
|
📸
RAG-AnythingMultimodal RAG |
🎥
VideoRAGExtreme Long-Context Video RAG |
✨
MiniRAGExtremely Simple RAG |
@article{guo2024lightrag,
title={LightRAG: Simple and Fast Retrieval-Augmented Generation},
author={Zirui Guo and Lianghao Xia and Yanhua Yu and Tu Ao and Chao Huang},
year={2024},
eprint={2410.05779},
archivePrefix={arXiv},
primaryClass={cs.IR}
}