
Hybrid RAG system combining vector search, knowledge graph (LightRAG), and cross-encoder reranking — with Docling document parsing, visual intelligence (image/table captioning), agentic streaming chat, and inline citations. Powered by Gemini or local Ollama models.
Copy the command below to clone the repository to your machine.
Upload documents. Ask questions. Get cited answers.
NexusRAG combines vector search, knowledge graph, and cross-encoder reranking into one seamless RAG pipeline — powered by Gemini, local Ollama, or fully offline sentence-transformers.
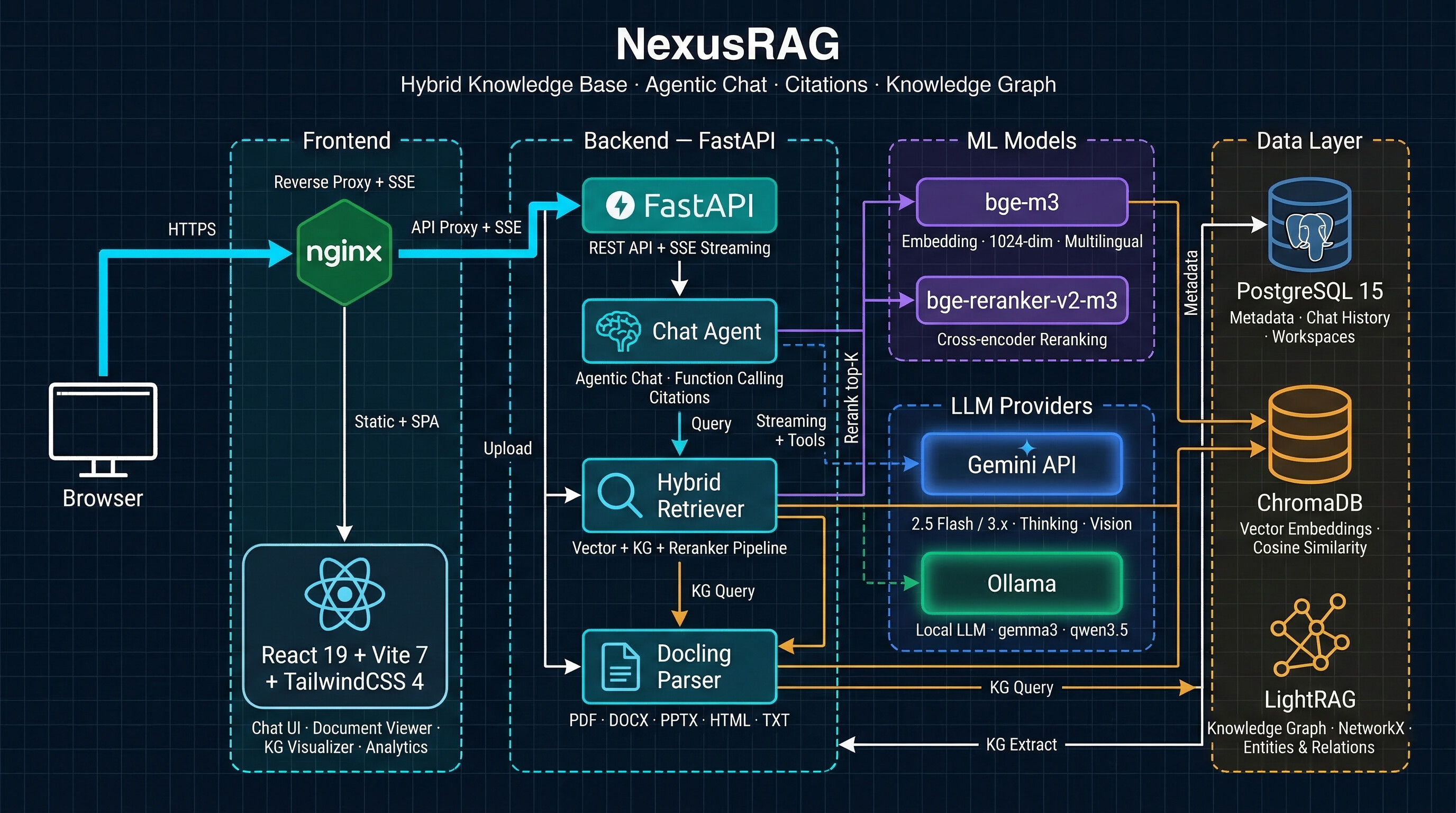
Most RAG systems follow a simple pipeline: split text → embed → retrieve → generate. NexusRAG goes further at every stage:
| Aspect | Traditional RAG | NexusRAG |
|---|---|---|
| Document Parsing | Plain text extraction, structure lost | Docling or Marker: preserves headings, page boundaries, formulas, layout — switchable via config |
| Images & Tables | Ignored entirely | Extracted, captioned by vision LLM, embedded as searchable vectors |
| Chunking | Fixed-size splits, breaks mid-sentence | Hybrid semantic + structural chunking (respects headings, tables) |
| Embeddings | Single model for everything | Dual-model: BAAI/bge-m3 (1024d, search) + KG embedding (Gemini 3072d / Ollama / sentence-transformers) |
| Retrieval | Vector similarity only | 3-way parallel: Vector over-fetch + KG entity lookup + Cross-encoder rerank |
| Knowledge | No entity awareness | LightRAG graph: entity extraction, relationship mapping, multi-hop traversal |
| Context | Raw chunks dumped to LLM | Structured assembly: KG insights → cited chunks → related images/tables |
| Citations | None or manual | Auto-generated 4-char IDs with page number and heading path |
| Page awareness | Lost after chunking | Preserved end-to-end: chunk → citation → document viewer navigation |
NexusRAG supports two document parsers, switchable via NEXUSRAG_DOCUMENT_PARSER env config:
| Feature | Docling (default) | Marker |
|---|---|---|
| Math/Formula | Basic (known LaTeX issues) | Superior LaTeX via Surya |
| GPU footprint | ~18-20GB VRAM (formula enrichment) | ~2-4GB VRAM |
| Formats | PDF, DOCX, PPTX, HTML | PDF, DOCX, PPTX, XLSX, HTML, EPUB |
| Chunking | HybridChunker (semantic + structural) | Heading-aware + page-based |
| Image extraction | Via Docling pipeline | Via Marker pipeline |
| Table extraction | Structured export | Markdown tables |
Both parsers share the same output contract (ParsedDocument) — downstream pipeline (dedup, embedding, KG, retrieval) works identically regardless of parser choice.
Common features across both parsers:
# Switch parser in .env
NEXUSRAG_DOCUMENT_PARSER=marker # or "docling" (default)
| Stage | Technology | Details |
|---|---|---|
| Vector Embedding | BAAI/bge-m3 | 1024-dim multilingual bi-encoder (100+ languages) |
| KG Embedding | Gemini / Ollama / sentence-transformers | Configurable: Gemini (3072d), Ollama, or local sentence-transformers (e.g. bge-m3 1024d) |
| Vector Search | ChromaDB | Cosine similarity, over-fetch top-20 candidates |
| Knowledge Graph | LightRAG | Entity/relationship extraction, keyword-to-entity matching |
| Reranking | BAAI/bge-reranker-v2-m3 | Cross-encoder joint scoring — encodes (query, chunk) pairs together |
| Generation | Gemini / Ollama | Agentic streaming chat with function calling |
Why two embedding models? Vector search needs speed (local bge-m3, 1024-dim). Knowledge graph extraction needs semantic richness for entity recognition — choose Gemini Embedding (3072-dim, cloud), Ollama, or sentence-transformers (fully local, no API needed). Each model is optimized for its role.
Retrieval flow:
Images and tables are embedded into chunk vectors — not stored separately. When the parser extracts an image on page 5, its LLM-generated caption is appended to the text chunks on that page before embedding. This means searching for "revenue chart" finds chunks that contain the chart description, without needing a separate image search index.
Image Pipeline
[Image on page 5]: Graph showing 12% revenue growth YoY[IMG-p4f2] referencesTable Pipeline
[Table on page 5 (3x4)]: Annual sales by regionEnhance RAG accuracy and organization by attaching custom key-value metadata during document upload:
year, category, or author without needing separate workspaces.custom_metadata (list of key-values) in the upload API, and metadata_filter in query/chat APIs.Every answer is grounded in source documents with 4-character citation IDs (e.g., [a3z1]):
[IMG-p4f2] with page trackingInteractive force-directed graph built from extracted entities and relationships:
Switch between cloud and local models with a single environment variable:
| Model | Best For | Thinking |
|---|---|---|
gemini-2.5-flash |
General chat, fast responses | Budget-based (auto) |
gemini-3.1-flash-lite |
High throughput, cost-effective Recommended default | Level-based: minimal / low / medium / high |
Extended thinking is automatically configured — Gemini 2.5 uses thinking_budget_tokens, Gemini 3.x uses thinking_level.
| Model | Parameters | Tool Calling | Recommendation |
|---|---|---|---|
gemma4:e4b |
4.5B effective (8B total) | Native | Recommended default — best quality/size ratio, 128K context, vision + thinking + native tool calling |
gemma4:e2b |
2.3B effective (5.1B total) | Native | Ultra-lightweight, fast responses. Needs thinking enabled for reliable tool calls |
qwen3.5:9b |
9B | Native | Good multilingual support, solid tool calling |
qwen3.5:4b |
4B | Native | Lightweight, works on 8GB RAM. May miss some tool calls |
gemma3:12b |
12B | Prompt-based | Best balance of quality and speed for older Ollama versions |
Tip: Gemma 4 models require Ollama v0.20.0+. NexusRAG auto-detects native tool calling support — models that support it use Ollama's native tools API (more reliable), others fall back to prompt-based tool calling automatically.
Tip: For Knowledge Graph extraction, larger models (12B+) produce significantly better entity/relationship quality. Smaller models (4B) may extract zero entities on complex documents.
Provider switching — Comment/uncomment blocks in .env:
# Cloud (Gemini)
LLM_PROVIDER=gemini
GOOGLE_AI_API_KEY=your-key
# Local (Ollama) — uncomment to switch
# LLM_PROVIDER=ollama
# OLLAMA_MODEL=gemma4:e4b
The Knowledge Graph embedding model is configured separately from the chat LLM:
| Provider | Config | API Required | Dimension |
|---|---|---|---|
| Gemini (default) | KG_EMBEDDING_PROVIDER=gemini |
Google AI API key | 3072 |
| Ollama | KG_EMBEDDING_PROVIDER=ollama |
Ollama server | Varies |
| sentence-transformers | KG_EMBEDDING_PROVIDER=sentence_transformers |
None (fully local) | Model-dependent (e.g. 1024 for bge-m3) |
# Fully local KG embeddings — no API or external service needed
KG_EMBEDDING_PROVIDER=sentence_transformers
KG_EMBEDDING_MODEL=BAAI/bge-m3
KG_EMBEDDING_DIMENSION=1024
Agentic Streaming ChatTip:
sentence_transformersreuses the sameBAAI/bge-m3model already downloaded for vector search — zero extra disk space, zero API costs, fully offline.
The chat system uses a semi-agentic architecture with real-time SSE streaming:
Theme & Layout
Chat Interface
Document Management
Search
Analytics Dashboard
Micro-interactions
/ to focus search, Enter to send, Escape to cancelNexusRAG was evaluated using two complementary methods: 16 hand-crafted tests (rule-based metrics) and 30 RAGAS synthetic tests (LLM-as-judge). Test corpus: TechVina Annual Report 2025 (Vietnamese, 26 chunks) + DeepSeek-V3.2 Technical Paper (English, 57 chunks).
Phase 1 — Hand-crafted Tests (Rule-based)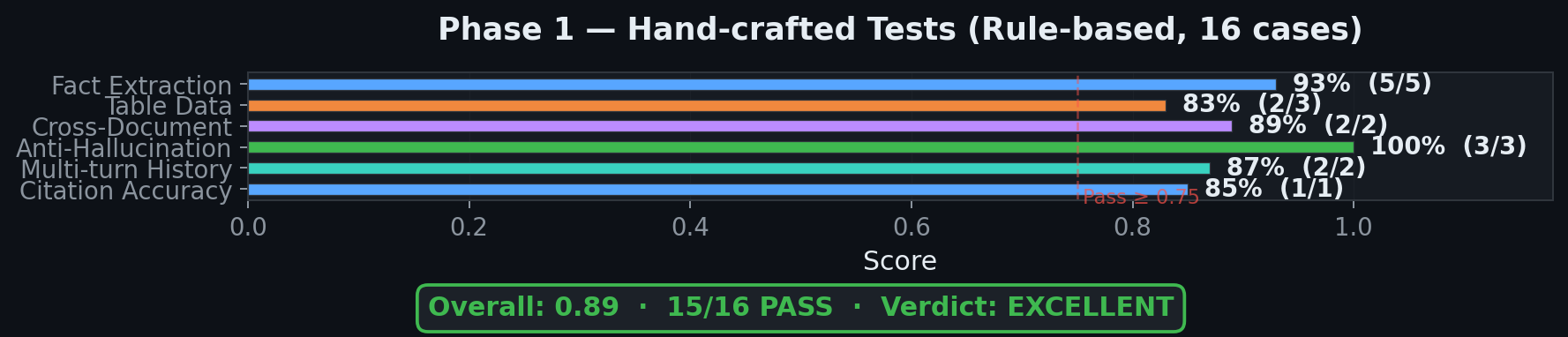
16 tests across 6 categories using 8 rule-based metrics (keyword coverage, refusal accuracy, citation format, language match, etc.) — no LLM judge involved.
| Category | Pass Rate | Avg Score |
|---|---|---|
| Fact Extraction (VI + EN) | 5/5 | 0.93 |
| Table Data | 2/3 | 0.83 |
| Cross-Document Reasoning | 2/2 | 0.89 |
| Anti-Hallucination | 3/3 | 1.00 |
| Multi-turn History | 2/2 | 0.87 |
| Citation Accuracy | 1/1 | 0.85 |
| Overall | 15/16 | 0.89 — EXCELLENT |
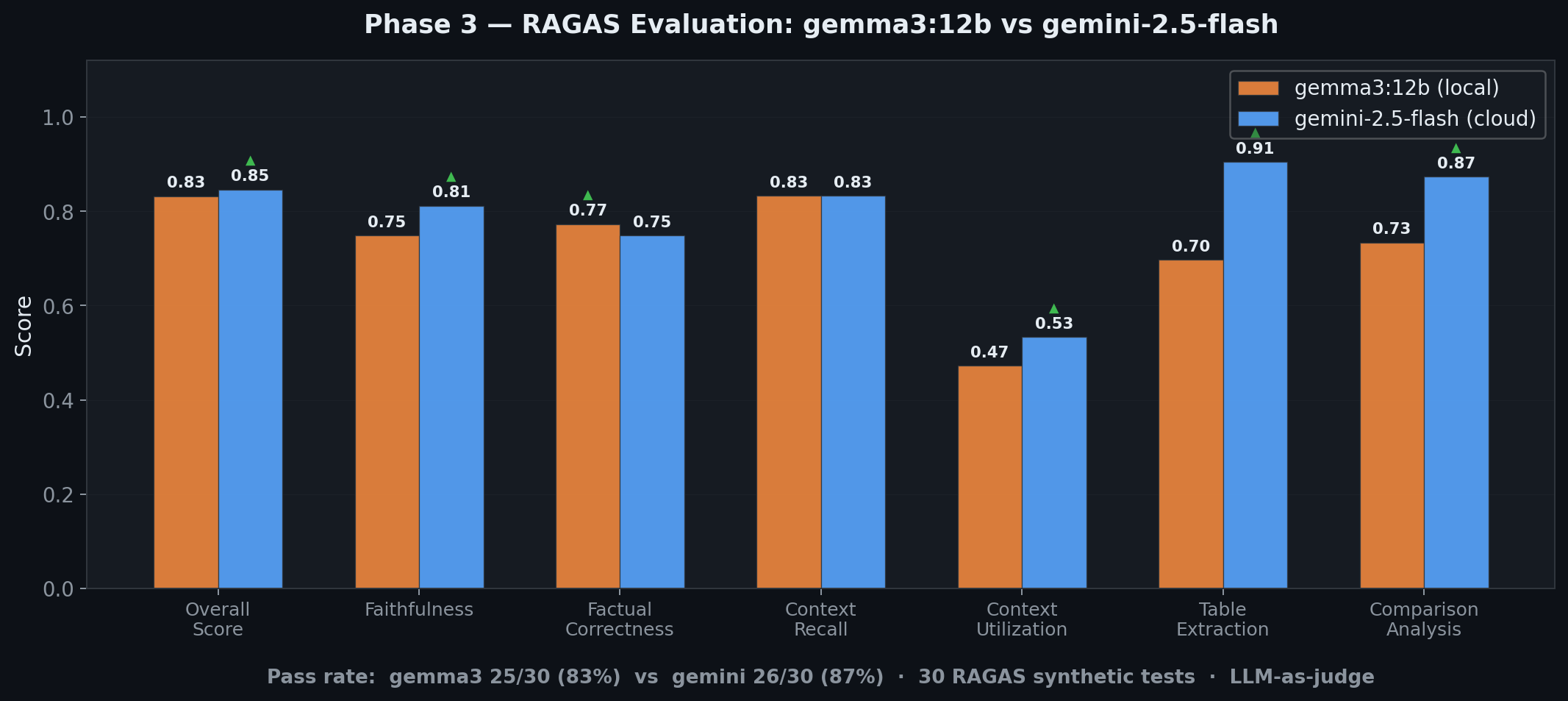
30 auto-generated Q&A pairs evaluated by Gemini 2.0 Flash as RAGAS judge. Same questions tested on both models:
| Metric | gemma3:12b (local) | gemini-2.5-flash (cloud) | Winner |
|---|---|---|---|
| Overall score | 0.832 | 0.846 | Gemini |
| Pass rate | 25/30 (83%) | 26/30 (87%) | Gemini |
| Faithfulness | 0.749 | 0.812 | Gemini (+0.063) |
| Factual correctness | 0.773 | 0.749 | gemma3 (+0.024) |
| Context recall | 0.833 | 0.833 | Tie |
| Table extraction | 0.697 | 0.905 | Gemini (+0.208) |
| Avg latency | 3076ms | 3283ms | gemma3 (-207ms) |
| Aspect | Status | Detail |
|---|---|---|
| Anti-hallucination | :green_circle: Strong | Perfect refusal on out-of-scope questions |
| Citation format | :green_circle: Strong | 100% correct format across all tests |
| Cross-doc reasoning | :green_circle: Strong | Successfully synthesizes across multiple sources |
| Table parsing | :yellow_circle: Model-dependent | gemma3 fails complex tables; Gemini handles well |
| Language consistency | :yellow_circle: Model-dependent | gemma3 occasionally responds in wrong language |
| Retrieval coverage | :red_circle: Weak | 5 cases with context_recall = 0 (specific facts missed by retrieval) |
| Faithfulness | :red_circle: Weak | 4 FAIL cases — LLM adds unsupported details when elaborating |
Planned EvaluationFull evaluation methodology and per-sample results:
rag_evaluation_report.md
Upcoming model benchmarks on the same 30 RAGAS test suite:
| Model | Type | Status |
|---|---|---|
| gemma3:12b | Local (Ollama) | :white_check_mark: Done |
| gemini-2.5-flash | Cloud (Google AI) | :white_check_mark: Done |
| qwen3.5:4b | Local (Ollama) | :hourglass: Planned |
| qwen3.5:9b | Local (Ollama) | :hourglass: Planned |
| gemini-3.1-flash-lite | Cloud (Google AI) | :hourglass: Planned |
Goal: compare cost-efficiency (local 4B/9B) vs cloud quality across faithfulness, table extraction, and multilingual consistency.
| Technology | Purpose |
|---|---|
| FastAPI | Async web framework with SSE streaming |
| SQLAlchemy 2.0 | Async ORM with PostgreSQL (asyncpg) |
| ChromaDB | Vector store — cosine similarity, per-workspace collections |
| LightRAG | Knowledge graph — entity extraction, multi-hop queries |
| Docling / Marker | Document parsing — PDF, DOCX, PPTX, HTML with structural extraction (switchable via config) |
| sentence-transformers | BAAI/bge-m3 embeddings + BAAI/bge-reranker-v2-m3 reranking |
| google-genai | Gemini API — chat, vision, function calling, extended thinking |
| ollama | Local LLM — tool calling via prompt tags, multimodal support |
| Technology | Purpose |
|---|---|
| React 19 + TypeScript 5.9 | UI framework with strict typing |
| Vite 7 | Dev server and production bundler |
| TailwindCSS 4 | Utility-first styling with dark / light theme |
| Zustand 5 | Lightweight state management |
| React Query 5 | Async data fetching, caching, and mutations |
| Framer Motion 12 | Layout animations, transitions, staggered entrances |
| react-markdown + KaTeX | Rich markdown with LaTeX math rendering |
| Lucide React | Icon library |
| Technology | Purpose |
|---|---|
| PostgreSQL 15 | Document metadata, chat history, workspace config |
| ChromaDB | Vector embeddings (HTTP client, containerized) |
| LightRAG | File-based KG (NetworkX + NanoVectorDB — no extra services) |
| Docker Compose | Full-stack deployment (4 containers) |
| nginx | Production frontend serving + API/SSE reverse proxy |
git clone https://github.com/LeDat98/NexusRAG.git
cd NexusRAG
cp .env.example .env
# Edit .env — set GOOGLE_AI_API_KEY (or switch to Ollama)
docker compose up -d
First build takes ~5-10 minutes (downloads ML models ~2.5GB). Open http://localhost:5174
git clone https://github.com/LeDat98/NexusRAG.git
cd NexusRAG
./setup.sh
The script checks prerequisites, creates venv, installs deps, starts PostgreSQL + ChromaDB, and optionally downloads ML models.
# Terminal 1 — Backend (port 8080)
./run_bk.sh
# Terminal 2 — Frontend (port 5174)
./run_fe.sh
| Resource | Minimum | Recommended |
|---|---|---|
| RAM | 4 GB | 8 GB+ |
| Disk | 5 GB | 10 GB+ |
| Python | 3.10+ | 3.11+ |
| Node.js | 18+ | 22 LTS |
| Docker | 20+ | Latest |
Copy .env.example and configure:
cp .env.example .env
| Variable | Description |
|---|---|
GOOGLE_AI_API_KEY |
Google AI API key (required for Gemini provider) |
| Variable | Default | Description |
|---|---|---|
LLM_PROVIDER |
gemini |
gemini or ollama |
LLM_MODEL_FAST |
gemini-2.5-flash |
Model for chat and KG extraction |
LLM_THINKING_LEVEL |
medium |
Gemini 3.x thinking: minimal / low / medium / high |
LLM_MAX_OUTPUT_TOKENS |
8192 |
Max output tokens (includes thinking) |
OLLAMA_HOST |
http://localhost:11434 |
Ollama server URL |
OLLAMA_MODEL |
gemma3:12b |
Ollama model name |
| Variable | Default | Description |
|---|---|---|
KG_EMBEDDING_PROVIDER |
gemini |
gemini, ollama, or sentence_transformers |
KG_EMBEDDING_MODEL |
text-embedding-004 |
Model name (provider-specific) |
KG_EMBEDDING_DIMENSION |
3072 |
Embedding dimension (must match model) |
| Variable | Default | Description |
|---|---|---|
NEXUSRAG_EMBEDDING_MODEL |
BAAI/bge-m3 |
Embedding model (1024-dim) |
NEXUSRAG_RERANKER_MODEL |
BAAI/bge-reranker-v2-m3 |
Cross-encoder reranker |
NEXUSRAG_VECTOR_PREFETCH |
20 |
Candidates before reranking |
NEXUSRAG_RERANKER_TOP_K |
8 |
Final results after reranking |
NEXUSRAG_ENABLE_KG |
true |
Enable knowledge graph extraction |
NEXUSRAG_DOCUMENT_PARSER |
docling |
Document parser: docling (default) or marker (lighter, better math) |
NEXUSRAG_MARKER_USE_LLM |
false |
Enable LLM-enhanced mode for Marker (better tables, equations) |
NEXUSRAG_ENABLE_IMAGE_EXTRACTION |
true |
Extract images from documents |
NEXUSRAG_ENABLE_IMAGE_CAPTIONING |
true |
LLM-caption images for search |
NEXUSRAG_KG_LANGUAGE |
Vietnamese |
KG extraction language |
NEXUSRAG_DOCUMENT_PARSER=marker env configNexusRAG includes a Model Context Protocol (MCP) server that exposes its core functionalities:
get_workspace_list: List all knowledge bases.get_document_by_id: Get details for a specific document.query: Query indexed documents using semantic search.The MCP Server is automatically started by default via docker-compose up -d on port 8000 using the Streamable HTTP transport (latest protocol version).
You can directly add the NexusRAG MCP server to Cursor or Claude as an SSE connection using the URL:http://localhost:8000/mcp
(Note: some clients still label this as an SSE connection, but use the /mcp endpoint to connect via Streamable HTTP).
All endpoints prefixed with /api/v1. Interactive docs at http://localhost:8080/docs
| Method | Endpoint | Description |
|---|---|---|
GET |
/workspaces |
List all workspaces |
POST |
/workspaces |
Create workspace |
PUT |
/workspaces/{id} |
Update workspace |
DELETE |
/workspaces/{id} |
Delete workspace + all data |
| Method | Endpoint | Description |
|---|---|---|
POST |
/documents/upload/{workspace_id} |
Upload file (supports custom_metadata) |
GET |
/documents/{id}/markdown |
Get parsed content |
GET |
/documents/{id}/images |
List extracted images |
DELETE |
/documents/{id} |
Delete document |
| Method | Endpoint | Description |
|---|---|---|
POST |
/rag/query/{workspace_id} |
Hybrid search (supports metadata_filter) |
POST |
/rag/chat/{workspace_id}/stream |
Agentic streaming chat (SSE) (supports metadata_filter) |
GET |
/rag/chat/{workspace_id}/history |
Chat history |
POST |
/rag/process/{document_id} |
Process document |
GET |
/rag/graph/{workspace_id} |
Knowledge graph data |
GET |
/rag/analytics/{workspace_id} |
Full analytics |
⭐ If you find NexusRAG useful, please consider giving it a star — it helps others discover the project and motivates continued development!
MIT License © 2026 Le Duc Dat